事务的几个概念:
A(atomicity)原子性
是指,一个事务里的多条SQL命令要么全部执行,要么全部不执行。
C(consistency)一致性
数据更改状态:及如果数据更新成功,要和预期值一致,如果失败要保持到更新之前的状态不变。
I (isolation) 隔离性
事务的隔离性要求每个读写事务的对象对其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,通常这使用锁来实现
D(isolation)持久性
事务的几个概念:
A(atomicity)原子性
是指,一个事务里的多条SQL命令要么全部执行,要么全部不执行。
C(consistency)一致性
数据更改状态:及如果数据更新成功,要和预期值一致,如果失败要保持到更新之前的状态不变。
I (isolation) 隔离性
事务的隔离性要求每个读写事务的对象对其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,通常这使用锁来实现
D(isolation)持久性
Snowflake 算法介绍
Snowflake 是由 Twitter 提出的一个分布式全局唯一 ID 生成算法,算法生成 ID 的结果是一个 64bit 大小的长整,标准算法下它的结构如下图: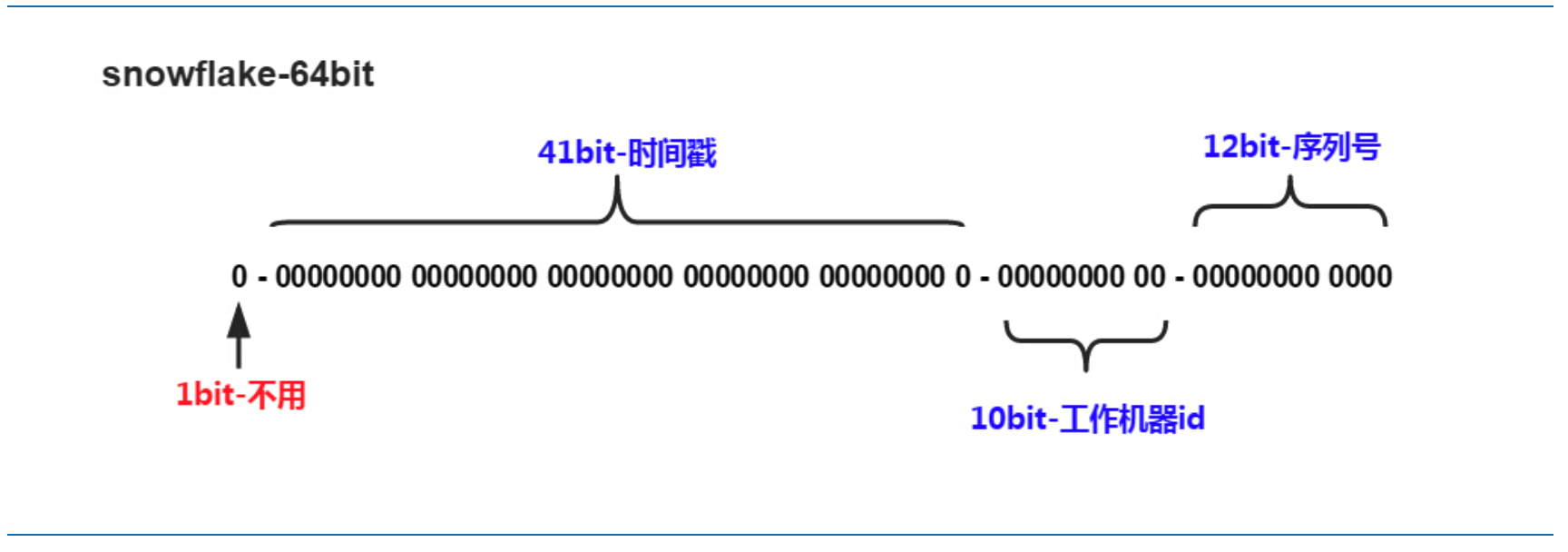
1 位,不用。
二进制中最高位为符号位,我们生成的 ID 一般都是正整数,所以这个最高位固定是 0。
41 位,用来记录时间戳(毫秒)。
41 位 可以表示 2^41 - 1 个数字。
也就是说 41 位 可以表示 2^41 - 1 个毫秒的值,转化成单位年则是 (2^41 - 1) / (1000 * 60 * 60 * 24 * 365) 约为 69 年。
10 位,用来记录工作机器 ID。
可以部署在 2^10 共 1024 个节点,包括 5 位 DatacenterId 和 5 位 WorkerId。
12 位,序列号,用来记录同毫秒内产生的不同 id。
12 位 可以表示的最大正整数是 2^12 - 1 共 4095 个数字,来表示同一机器同一时间截(毫秒)内产生的 4095 个 ID 序号。
Snowflake 可以保证:
所有生成的 ID 按时间趋势递增。
整个分布式系统内不会产生重复 ID(因为有 DatacenterId (5 bits) 和 WorkerId (5 bits) 来做区分)。
PHP 数组的底层实现是散列表(也叫 hashTable ),散列表是根据键(Key)直接访问内存存储位置的数据结构,它的 key - value 之间存在一个映射函数,可以根据 key 通过映射函数得到的散列值直接索引到对应的 value 值,无需通过关键字比较,在理想情况下,不考虑散列冲突,散列表的查找效率是非常高的,时间复杂度是 O (1)。
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
看一个例子:
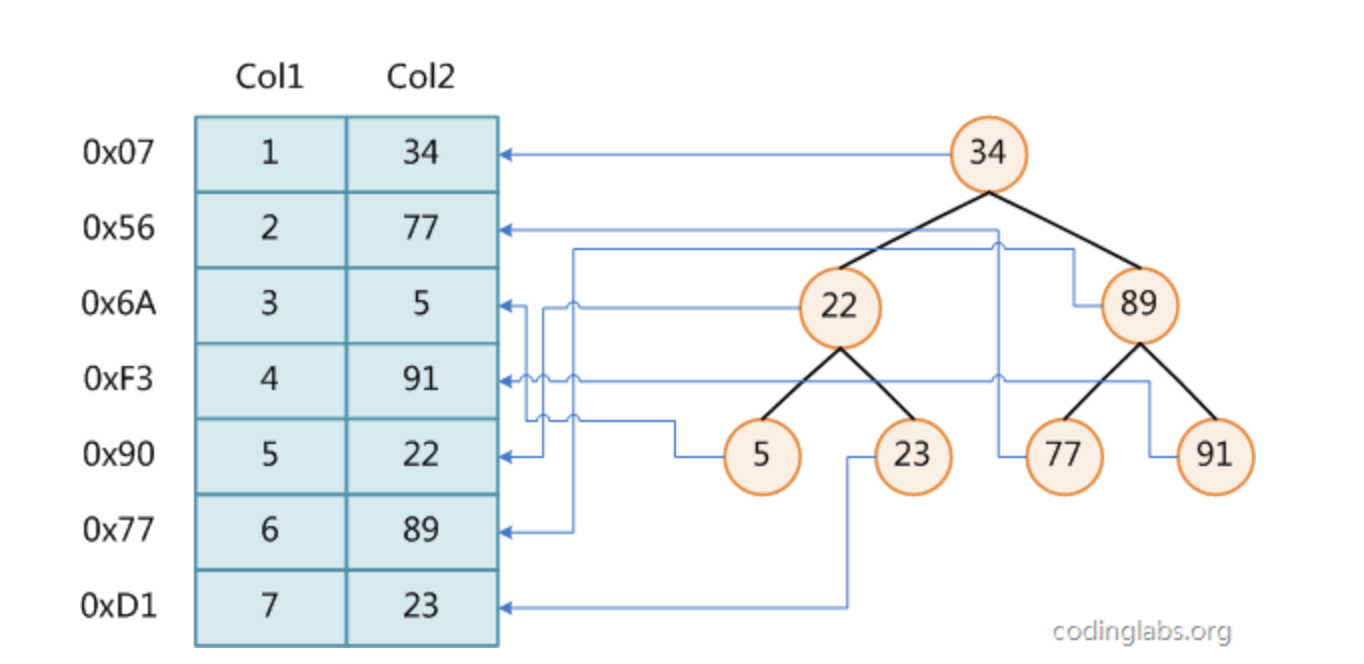
图1展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在(O(log_2n))的复杂度内获取到相应数据。
虽然这是一个货真价实的索引,但是实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现的,原因会在下文介绍。
先看看几种树形结构: