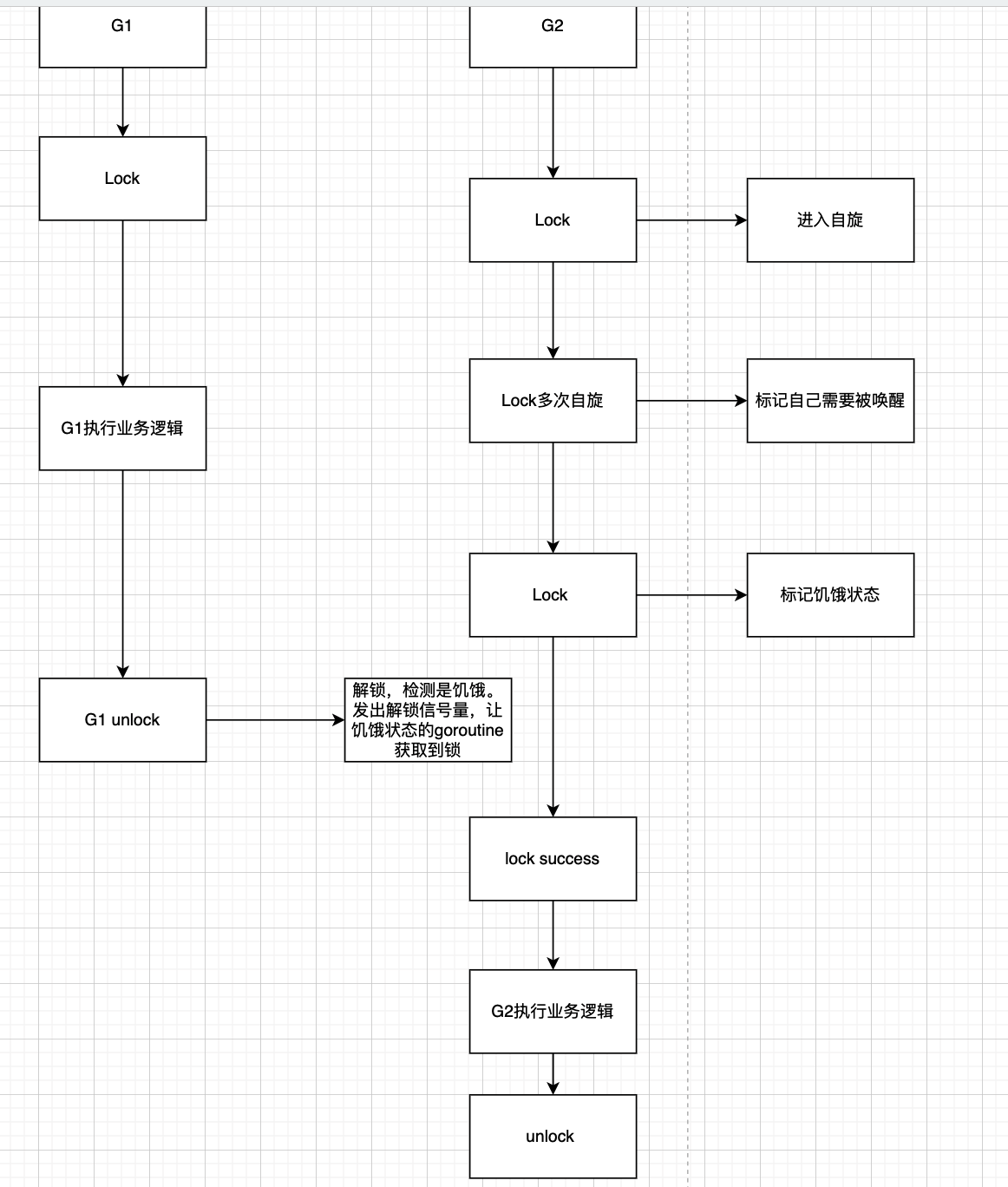
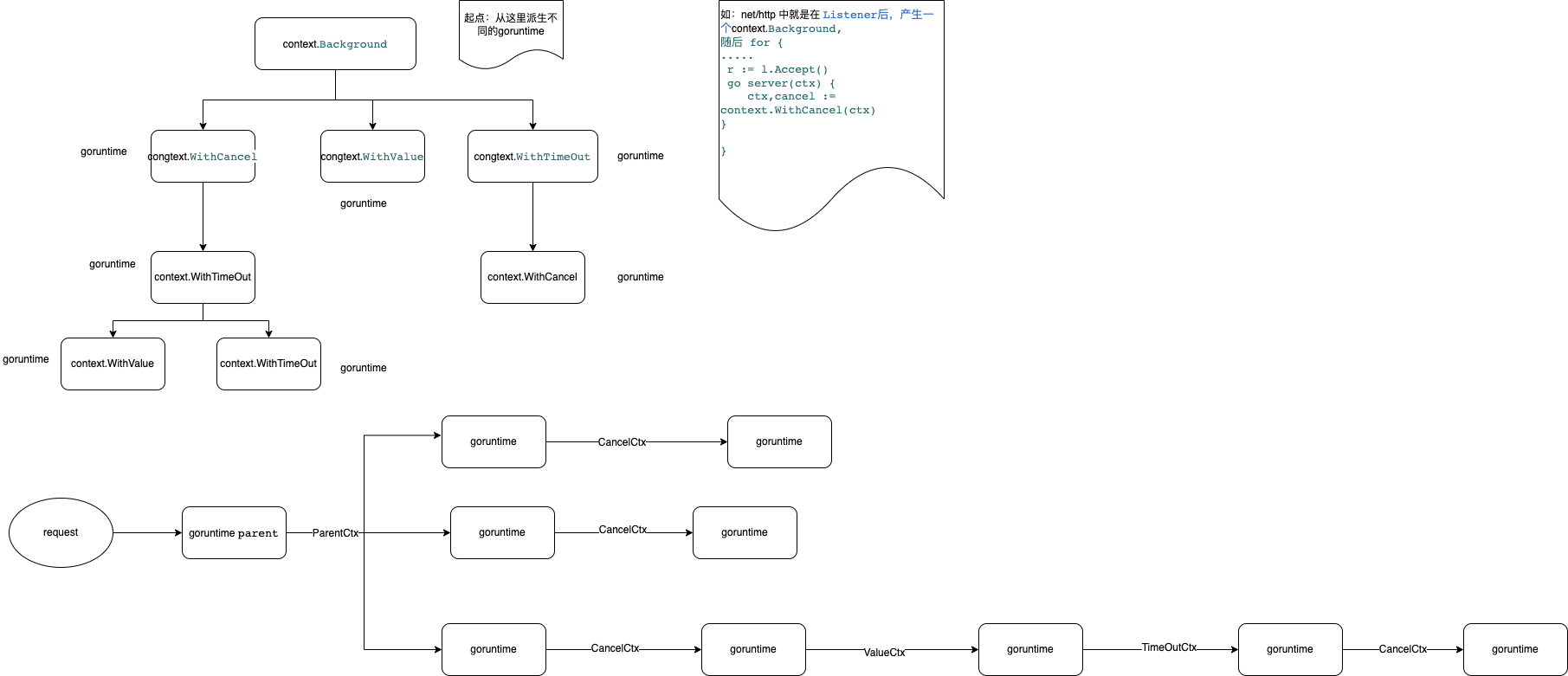
什么是DDD:
领域驱动设计(Domain-Driven Design,简称DDD)是一种软件设计方法,旨在帮助开发者有效地构建复杂的软件系统,特别是那些与业务领域紧密相关的应用程序。DDD 强调通过深入理解业务领域的本质和规则来构建软件系统,以便软件能够更好地反映和支持业务需求。是以业务视角来规划系统架构,使系统架构更好的服务于业务的一套指导方法论。
DDD定义的相关概念:
边界上下文:
一个由显示边界限定的特定职责。领域模型便存在于这个边界之内。在边界内,每一个模型概念,包括它的属性和操作,都具有特殊的含义。 边界上下文是一组基于业务角度定义的一些通用相关语言,包含了一个完整的业务流程里。是为了使业务和技术具有统一沟通术语和限定业务边界而出现。也就是说确定了边界上下文也就是确定了业务边界。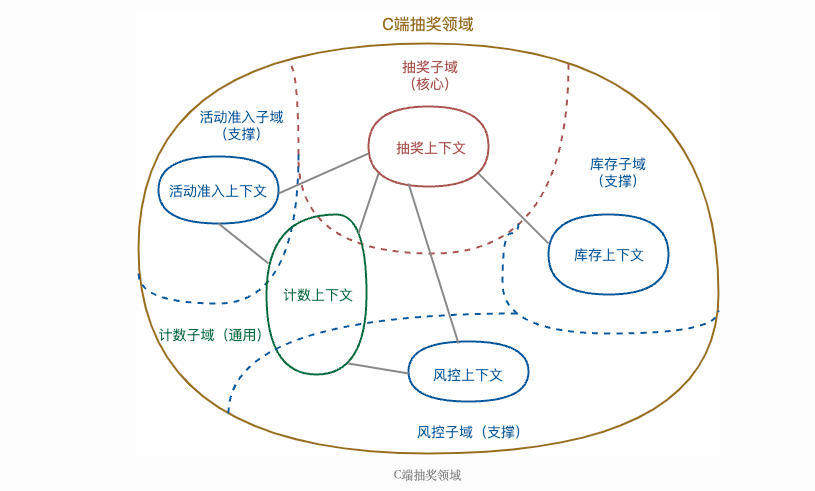
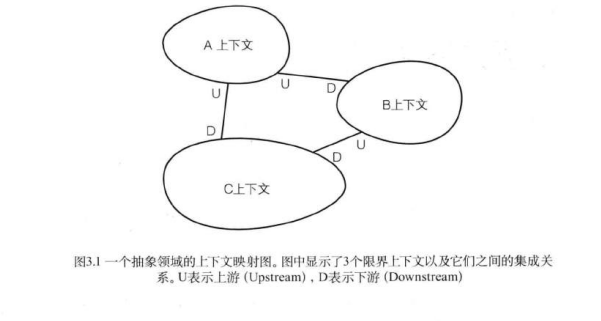
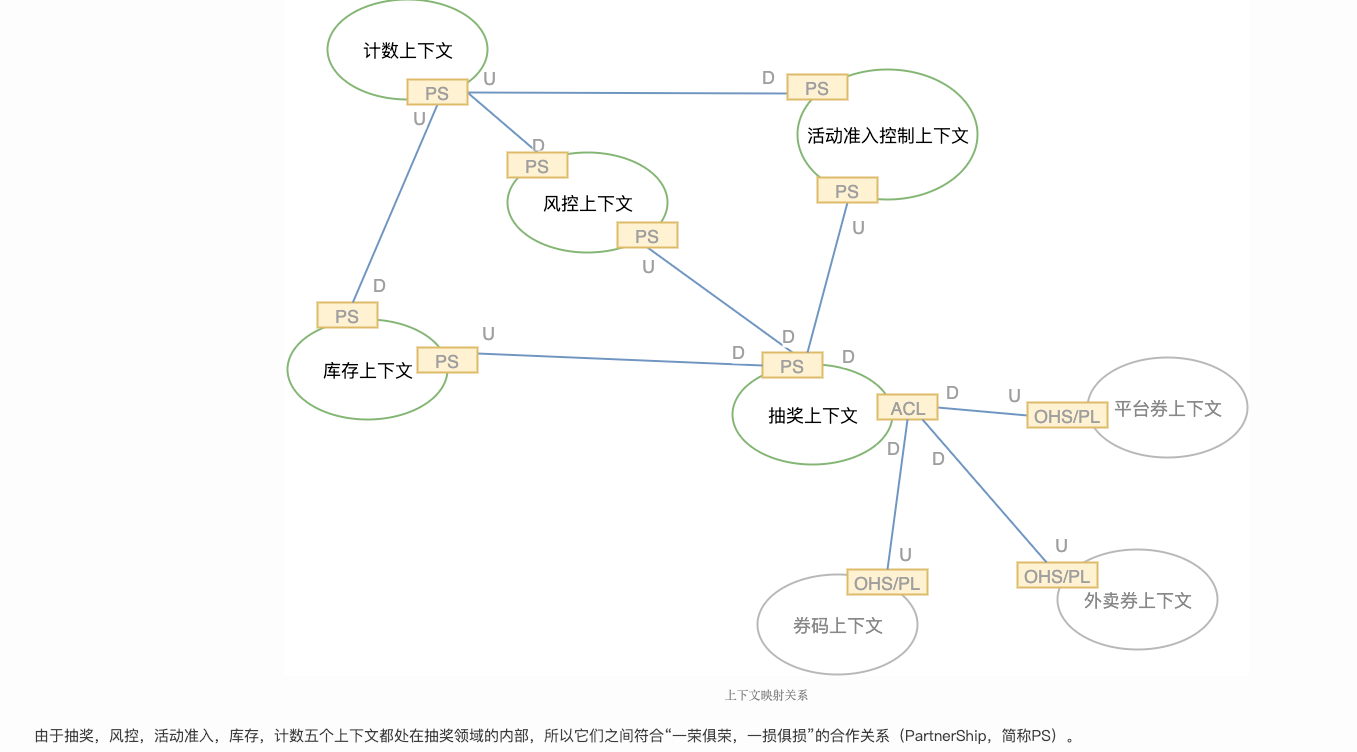
限界上下文之间的映射关系
- 合作关系(Partnership):两个上下文紧密合作的关系,一荣俱荣,一损俱损。
- 共享内核(Shared Kernel):两个上下文依赖部分共享的模型。
- 客户方-供应方开发(Customer-Supplier Development):上下文之间有组织的上下游依赖。
- 遵奉者(Conformist):下游上下文只能盲目依赖上游上下文。
- 防腐层(Anticorruption Layer):一个上下文通过一些适配和转换与另一个上下文交互。
- 开放主机服务(Open Host Service):定义一种协议来让其他上下文来对本上下文进行访问。
- 发布语言(Published Language):通常与OHS一起使用,用于定义开放主机的协议。
- 大泥球(Big Ball of Mud):混杂在一起的上下文关系,边界不清晰。
- 另谋他路(SeparateWay):两个完全没有任何联系的上下文。
领域:
领域就是业务知识,它包括业务规则、实体、值对象、聚合、库存、服务等,以及与这些概念相关的关系和交互。是具体指向一个特定的业务领域。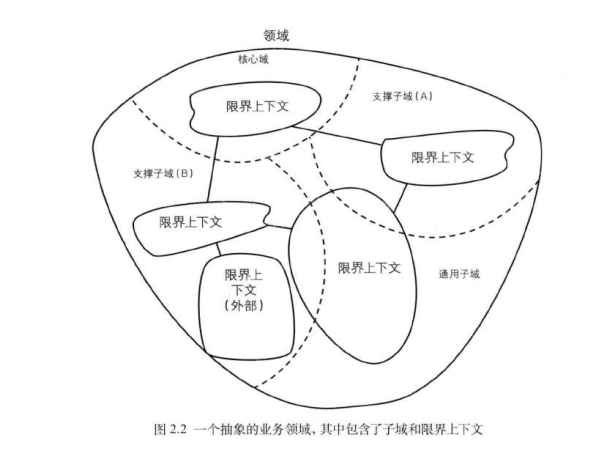
领域服务:
领域服务是一个动作,是一个业务具体的实施过程。对领域对象进行转换或者以多个对象进行计算返回一个值对象。总的来说领域服务是处理业务逻辑。
领域需要协调多个领域对象共同完成这个操作或动作。如果强行将这些操作职责分配给任何一个对象,则被分配的对象就是承担一些不该承担的职责,从而会导致对象的职责不明确很混乱。但是基于类的面向对象语言规定任何属性或行为都必须放在对象里面。所以我们需要寻找一种新的模式来表示这种跨多个对象的操作,DDD认为服务是一个很自然的范式用来对应这种跨多个对象的操作,所以就有了领域服务这个模式。和领域对象不同,领域服务是以动词开头来命名的,比如资金转帐服务可以命名为MoneyTransferService。当然,你也可以把服务理解为一个对象,但这和一般意义上的对象有些区别。因为一般的领域对象都是有状态和行为的,而领域服务没有状态只有行为。需要强调的是领域服务是无状态的,它存在的意义就是协调领域对象共完成某个操作,所有的状态还是都保存在相应的领域对象中.
最直观的现象是当两个对象有牵连或者依赖的操作时候,且感觉别扭的时候,最好把这个操作放到领域层。实体(entity):
实体是具有唯一标识的对象,其状态和行为与业务领域相关。实体通常具有生命周期,并且可以经历不同的状态变化。entity是基于领域逻辑的实体类,它的字段和数据库储存不需要有必然的联系。Entity包含数据,同时也应该包含行为,是充血模型。值对象:
值没有唯一标识且不可变的对象,它具有不变性、相等性和可替换性。
如地址相对于用户来说,单独就地址具有唯一性,但是放在人的从属性上是一旦确定是不会再有地址属性的变化的。在实践中,需要保证值对象创建后就不能被修改,即不允许外部再修改其属性。在不同上下文集成时,会出现模型概念的公用,如商品模型会存在于电商的各个上下文中。在订单上下文中如果你只关注下单时商品信息快照,那么将商品对象视为值对象是很好的选择。聚合根:
聚合是一组相关对象的集合,其中一个对象被指定为聚合根,用于管理整个聚合。这有助于维护领域对象之间的一致性.
比如相对于订单来说,有订单数据,订单关联的子单,订单关联的商品。 比如商品表和商品sku。
聚合由根实体,值对象和实体组成。如何创建好的聚合?
- 边界内的内容具有一致性:在一个事务中只修改一个聚合实例。如果你发现边界内很难接受强一致,不管是出于性能或产品需求的考虑,应该考虑剥离出独立的聚合,采用最终一致的方式。
- 设计小聚合:大部分的聚合都可以只包含根实体,而无需包含其他实体。即使一定要包含,可以考虑将其创建为值对象。
- 通过唯一标识来引用其他聚合或实体:当存在对象之间的关联时,建议引用其唯一标识而非引用其整体对象。如果是外部上下文中的实体,引用其唯一标识或将需要的属性构造值对象。 如果聚合创建复杂,推荐使用工厂方法来屏蔽内部复杂的创建逻辑。
聚合内部多个组成对象的关系可以用来指导数据库创建,但不可避免存在一定的抗阻。如聚合中存在List<值对象>,那么在数据库中建立1:N的关联需要将值对象单独建表,此时是有id的,建议不要将该id暴露到资源库外部,对外隐蔽。
领域事件:
领域事件由实战领域驱动设计一书提出,领域事件用于在领域内部和不同限界上下文之间传递信息。它们用于通知系统中发生的重要事件。
领域事件有助于降低系统内部各个领域对象之间的耦合度,因为它们提供了一种松散耦合的通信机制。这使得系统更容易维护、扩展和修改,因为领域对象之间的依赖性降低了。
领域事件还可用于构建系统的历史记录和审计功能。通过捕捉所有重要的领域变化事件,可以轻松地跟踪系统状态的演变,并在需要时进行审计。
领域事件常常与事件驱动架构(Event-Driven Architecture)结合使用。在这种架构中,系统中的各个组件通过发布和订阅事件的方式进行通信。当某个领域对象的状态发生变化时,它会发布一个相关的领域事件,而其他订阅了这个事件的组件会被通知并采取相应的行动。