缓存的使用
从系统层面看,使用缓存的目的无外乎缓解 DB 压力(主要是读压力),提升服务响应速度。
引入缓存,就不可避免地引入了缓存与业务 DB 数据的一致性问题,而不同的业务场景,对数据一致性的要求也不同。
因为redis和db毕竟是两套系统,数据的一致性想要达到何种程度要根据业务场景来取舍:
- 最终一致性分布式缓存场景
对于业务场景对数据一致性要求不是那么高的情况下,我们可以通过队列,binlog等手段达到最终一致性的效果。 - 强一致性分布式缓存场景
数据库跟缓存,以Mysql跟Redis举例,毕竟是两套系统,如果要保证强一致性,势必要引入2PC或Paxos等分布式一致性协议,或者是分布式锁等等,这个在实现上是有难度的,而且一定会对性能有影响。
而且如果真的对数据的一致性要求这么高,我们需要考虑 缓存是否真的有必要,直接读写数据库不是更好?以何种模式做到数据库跟缓存的数据强一致性,并且对系统是有提升的。
数据库和缓存的读写顺序
一般我们在操作数据库和缓存的时候,都是先读缓存,缓存没有了,去读数据库,然后写入缓存。大致步骤情况如下。
- 过期数据:程序先从缓存中读取数据,如果没有命中,则从数据库中读取,成功之后将数据放到缓存中
- 命中缓存:程序先从缓存中读取数据,如果命中,则直接返回
- 更新数据:程序先更新数据库,在删除缓存
再这里,不过多讨论,数据更新的其他方式。如
先更新缓存,在更新数据,【数据库可能回滚,这个时候还是要删除缓存】
先更新数据,在更新缓存。【两个线程同时更新的情况,有可能时序上出现错乱,导致不是最新数据】
先删除缓存,在更新数据。【数据未更新完成的情况,会有老数据写入缓存】
然而,我们在执行 更新数据和过期数据重新设置缓存的,在并发情况下会出现时序问题,造成缓存写入的不一定是最新数据。
- 当缓存失效时,同时有一个读请求和写请求或者读请求在写未完毕的过程中,此时读到的是old数据,并且由于时序原因【网络等各种情况导致的】,导致写入的操作在删除操作之后,会写入老数据。
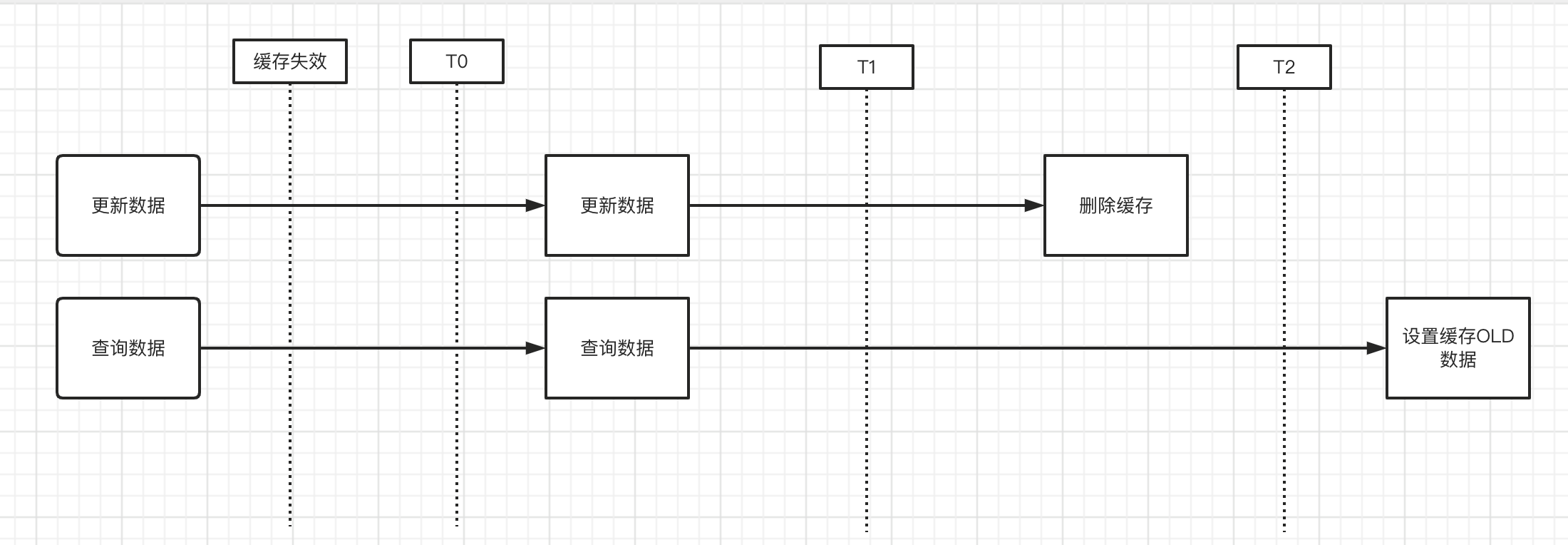
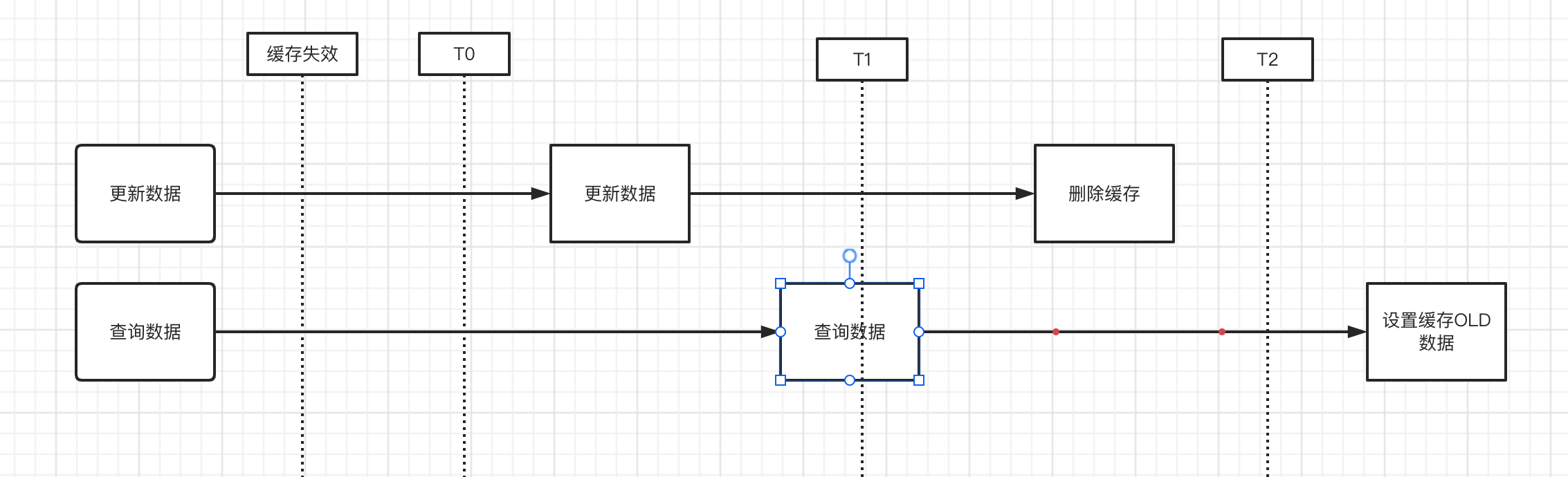
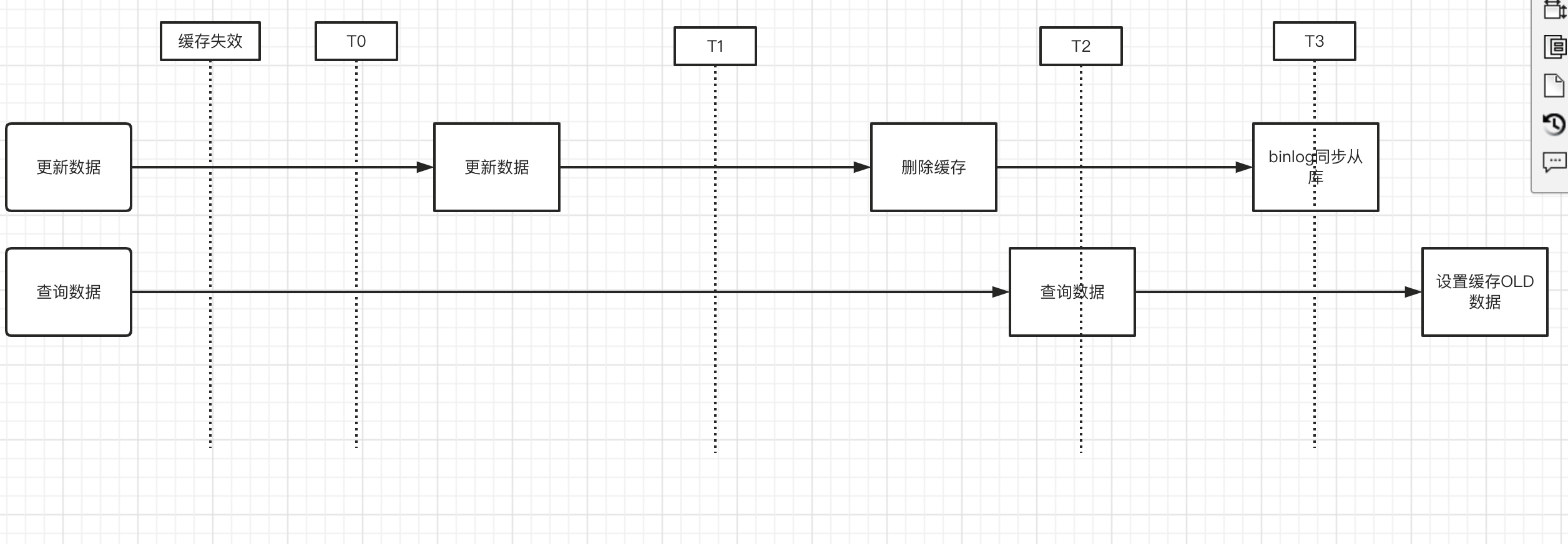
对于此种情况,如果对数据一致性没那么敏感的情况下,我们可以考虑设置的缓存时间短一些,
在有从库情况下考虑监听binlog下情况,在数据同步后在执行一次删除缓存的操作。
或者用一个key 表明数据处在主从延迟同步的情况,需要从主库读取,如果有数据库代理中间件,在中间内做这个操作是最好的。
数据库和缓存的一致性
如果想达到强一致的情况,我们必须考虑加锁降请求串行化执行,在设置缓存的过程中,会降低一定的系统负载。
而且删除和设置缓存都需要加锁。如下图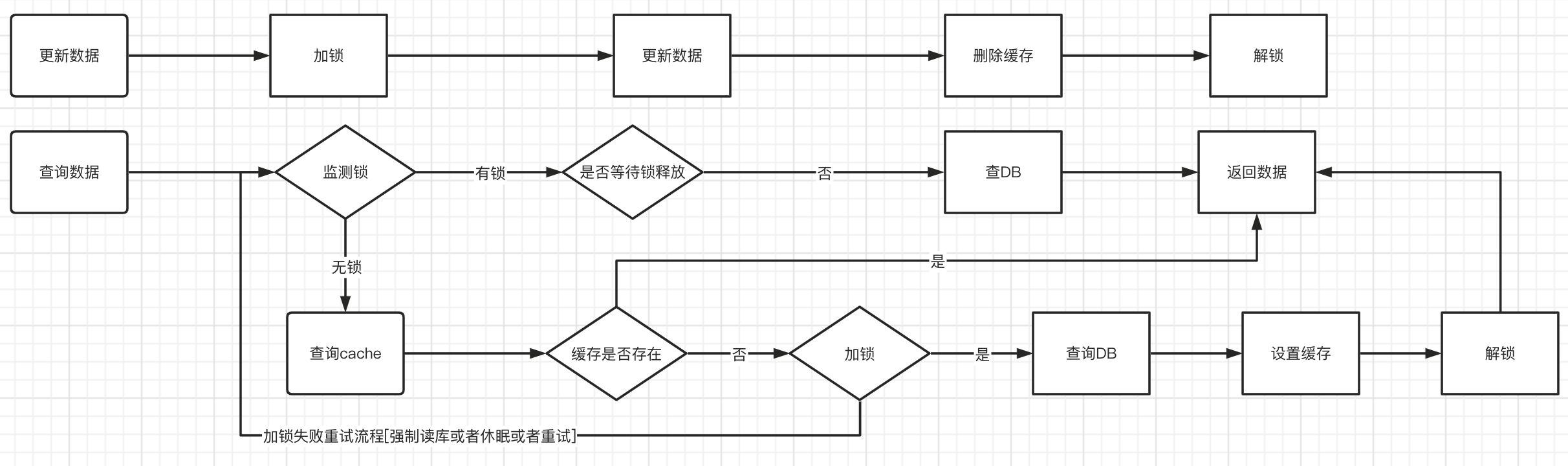
当更新数据或者更新缓存的时候:
在更新时候先尝试进行加锁,若当前有锁说明当前有 DB 或缓存正在更新,则进行等待和重试,从而可避免查询到 DB 中的老数据更新到缓存中。这种方案适合写并发低的场景。
读的并发操作控制:
在进行读的时候,先查验锁,如果锁不存在。说明无更新缓存和更新DB的操作。此时如果缓存有数据直接读取,无数据加锁重新设置缓存即可。
在有锁的时候。说明有更新数据或者设置缓存的操作正在执行。不能直接查询缓存,可以系统 配置在查询 DB 后返回数据或者检测到有锁后可进行短暂的等待和重试,好处是可进一步增加缓存的命中率,但是多一次锁等待,可能会影响到查询接口的性能。
锁在DB操作中的粒度: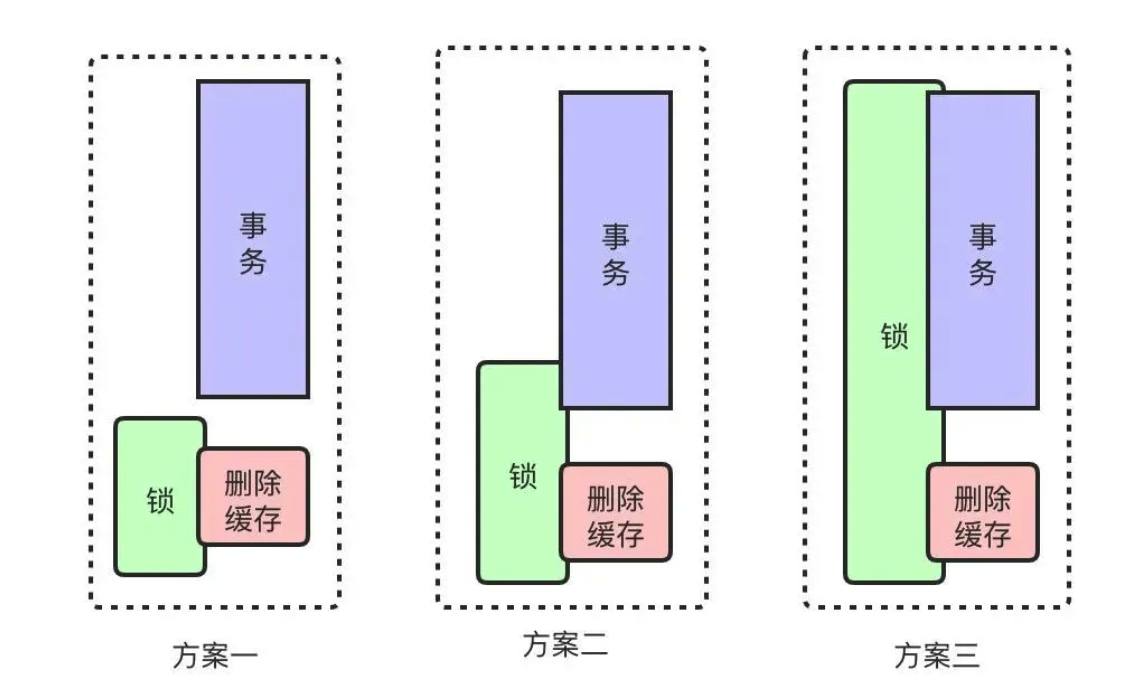
- 方案一:事务提交后加锁,只锁定删除缓存操作。对原事务无任何额外影响,但是在事务提交后到删除缓存之间存在与查询的并发可能性。
- 方案二:在事务提交前加锁,删除缓存后解锁。在满足一致性要求的前提下,锁的粒度可以做到最小,但是增加了 DB 事务的范围,若 redis 出现超时则可能导致事务时间拉长,进而影响 DB 操作性能。
- 方案三:在事务开始前加锁,删除缓存后解锁。锁的范围较大,但是能满足我们一致性要求,对单个 DB 事务也基本无影响。且对同一个用户来说,贷前数据的更新并不频繁,锁范围稍大一些是我们可以接受的。
此外还需要考虑如果有从库的情况下的主从延迟情况,如果延迟过大,在db更新后,需要标记下数据在主从延迟的时间下范围内是从主库读取。