记fasthttp-workerpool的实现方式:
golang中官方自带的net/http 默认处理请求的方式,对于一个http请求会单独的新起一个协程去做处理。在请求量大的时候,会使goroutine数量巨大,会增加runtime层的上下文切换成本,调度负担。而fasthttp 使用了workerpool规避这些问题。
fastHTTP的请求流程的处理
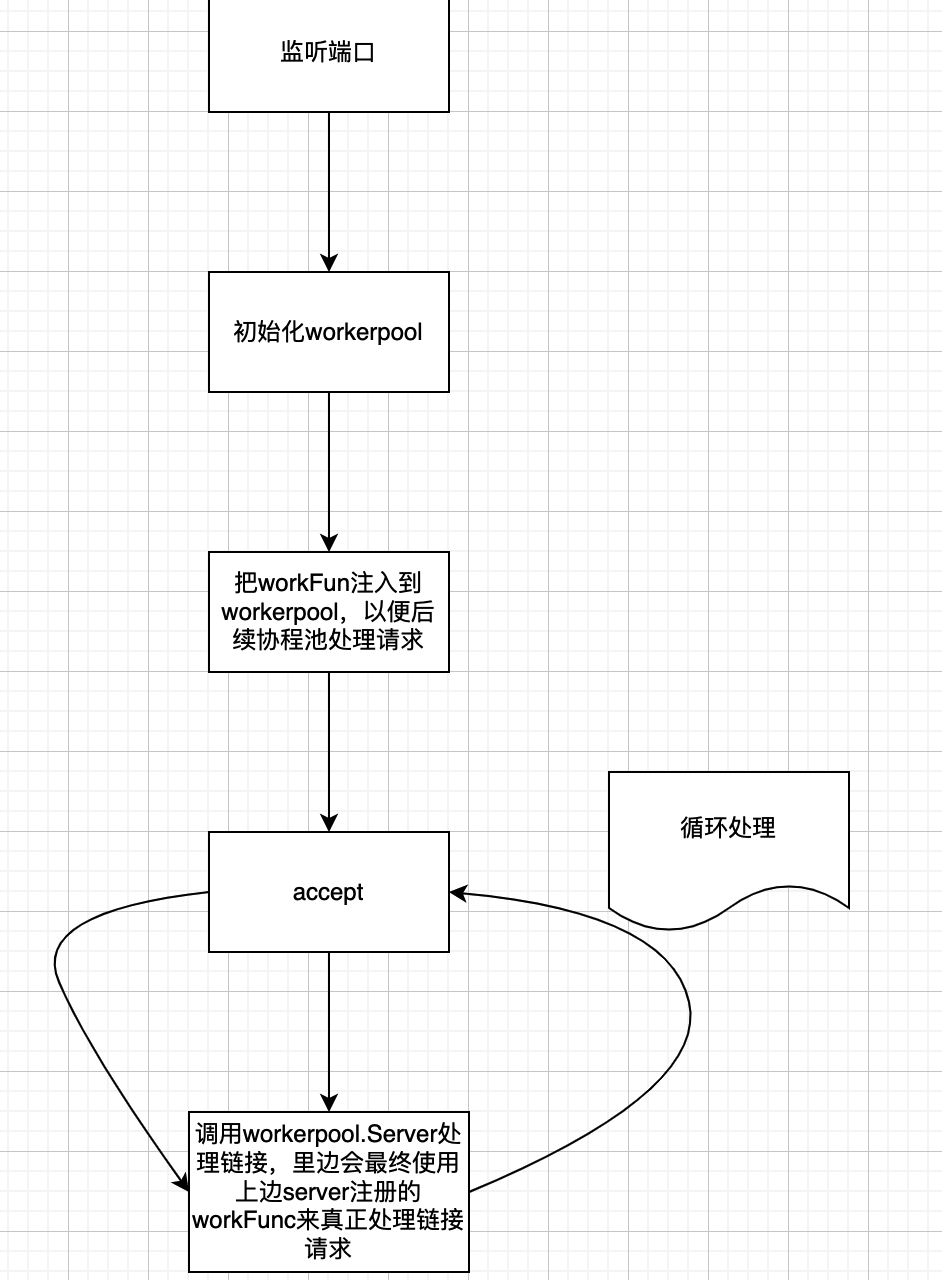
fasthttp的server启动时候,主要做了
- 监听端口
- 启动wokerpool
- 把真正处理链接的workFun注册到协程池里
- 循环接受HTTP链接,然后调用wp.Serve去处理HTTP链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66func (s *Server) Serve(ln net.Listener) error {
var lastOverflowErrorTime time.Time
var lastPerIPErrorTime time.Time
var c net.Conn
var err error
// 协程池大小
maxWorkersCount := s.getConcurrency()
s.mu.Lock()
{
s.ln = append(s.ln, ln)
if s.done == nil {
s.done = make(chan struct{})
}
if s.concurrencyCh == nil {
s.concurrencyCh = make(chan struct{}, maxWorkersCount)
}
}
s.mu.Unlock()
wp := &workerPool{
WorkerFunc: s.serveConn, // 注册真正处理HTTP链接的函数
MaxWorkersCount: maxWorkersCount,
LogAllErrors: s.LogAllErrors,
MaxIdleWorkerDuration: s.MaxIdleWorkerDuration,
Logger: s.logger(),
connState: s.setState,
}
// 启动协程池管理,start函数里会触发一个单独的协程用来清理那些过期的协程
wp.Start()
atomic.AddInt32(&s.open, 1)
defer atomic.AddInt32(&s.open, -1)
for {
if c, err = acceptConn(s, ln, &lastPerIPErrorTime); err != nil {
wp.Stop()
if err == io.EOF {
return nil
}
return err
}
s.setState(c, StateNew)
atomic.AddInt32(&s.open, 1)
//wp.Serve 里会从协程池里获取协程worker,然后去处理HTTP链接
if !wp.Serve(c) {
atomic.AddInt32(&s.open, -1)
s.writeFastError(c, StatusServiceUnavailable,
"The connection cannot be served because Server.Concurrency limit exceeded")
c.Close()
s.setState(c, StateClosed)
if time.Since(lastOverflowErrorTime) > time.Minute {
s.logger().Printf("The incoming connection cannot be served, because %d concurrent connections are served. "+
"Try increasing Server.Concurrency", maxWorkersCount)
lastOverflowErrorTime = time.Now()
}
if s.SleepWhenConcurrencyLimitsExceeded > 0 {
time.Sleep(s.SleepWhenConcurrencyLimitsExceeded)
}
}
c = nil
}
}workerpool主要的作用逻辑
wokerpool主要做了以下这些事情 - 管理协程worker,清楚过去的worker
- 使用自身的属性read来存储 worker
- HTTP链接和worker使用channel来传递
- 接受来自server注册的真正处理链接的函数workFun
自身主要结构如下图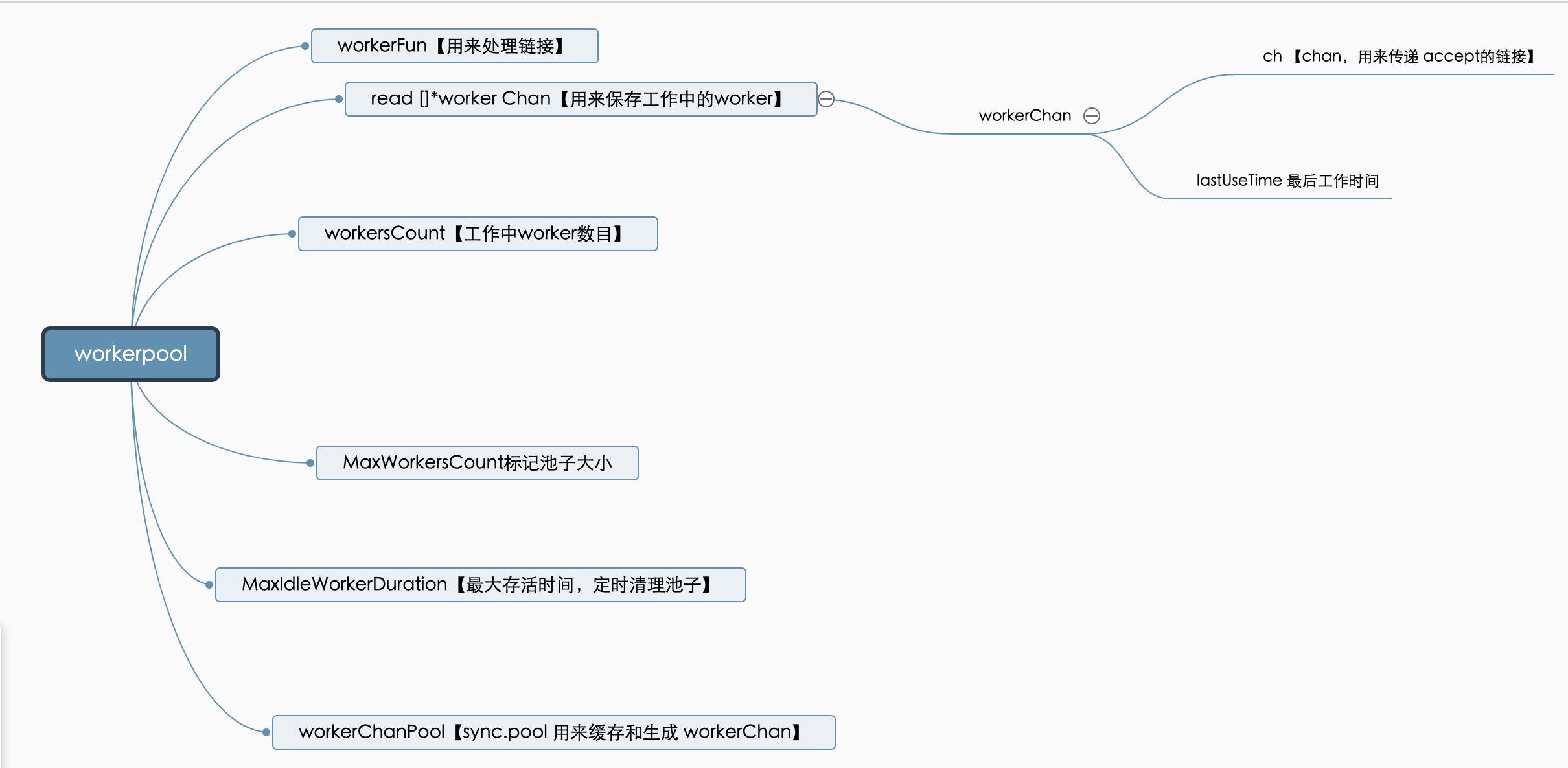
处理流程如下图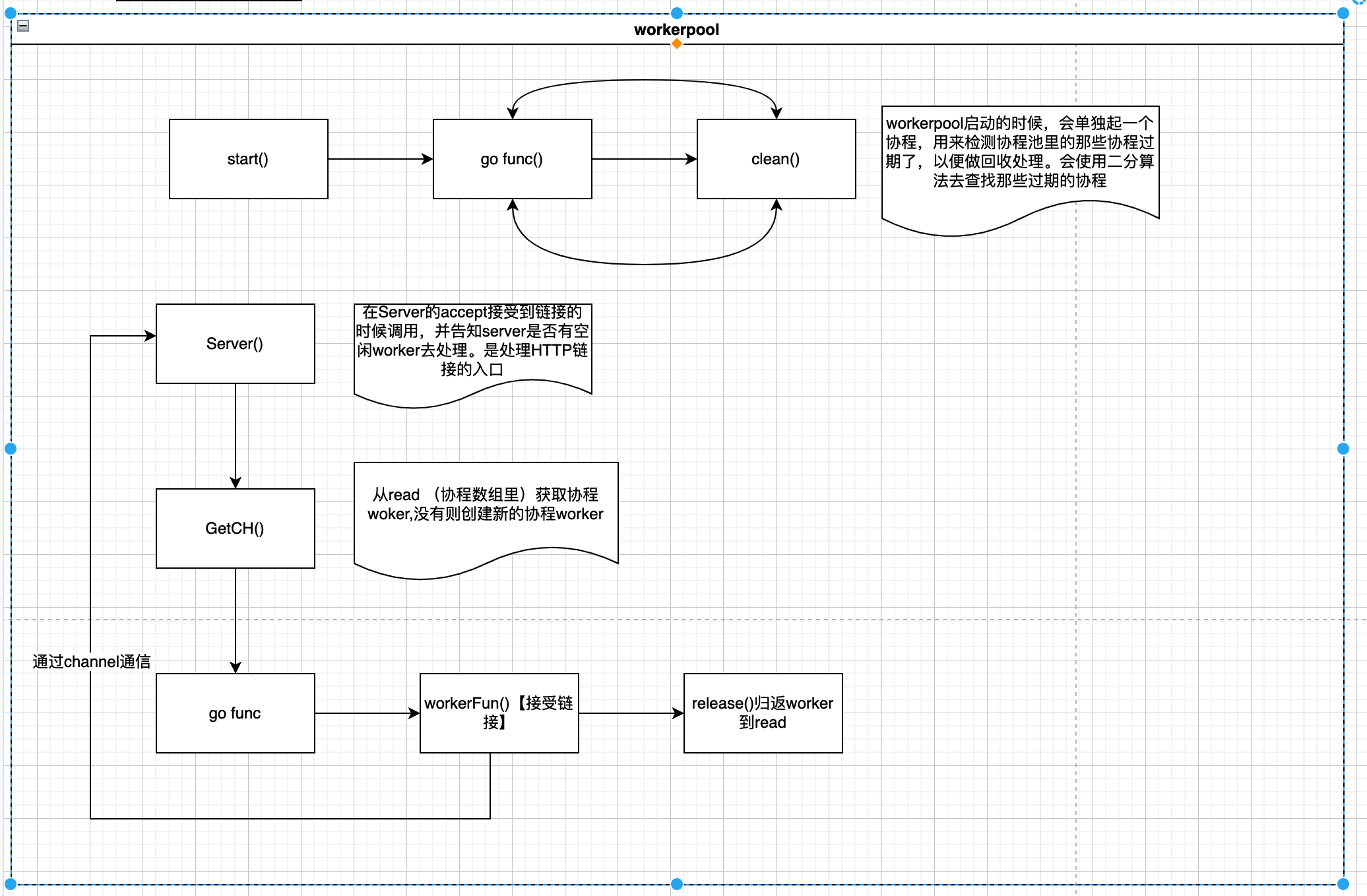
workerpool主要函数及属性分析
- start函数
主要单独起一个协程处理过期的worker,并且初始化了sync.pool的新增worker的方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26func (wp *workerPool) Start() {
if wp.stopCh != nil {
panic("BUG: workerPool already started")
}
wp.stopCh = make(chan struct{})
stopCh := wp.stopCh
// 使用sync.pool 来复用workerChan
wp.workerChanPool.New = func() interface{} {
return &workerChan{
ch: make(chan net.Conn, workerChanCap),
}
}
// 主要单独起一个协程处理过期的worker
go func() {
var scratch []*workerChan
for {
wp.clean(&scratch)
select {
case <-stopCh:
return
default:
time.Sleep(wp.getMaxIdleWorkerDuration())
}
}
}()
} - clean 主要是清理过期的worker
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38func (wp *workerPool) clean(scratch *[]*workerChan) {
maxIdleWorkerDuration := wp.getMaxIdleWorkerDuration()
criticalTime := time.Now().Add(-maxIdleWorkerDuration)
wp.lock.Lock()
ready := wp.ready
n := len(ready)
// 使用二分查找,发现过期的worker
l, r, mid := 0, n-1, 0
for l <= r {
mid = (l + r) / 2
if criticalTime.After(wp.ready[mid].lastUseTime) {
l = mid + 1
} else {
r = mid - 1
}
}
i := r
if i == -1 {
wp.lock.Unlock()
return
}
*scratch = append((*scratch)[:0], ready[:i+1]...)
m := copy(ready, ready[i+1:])
for i = m; i < n; i++ {
ready[i] = nil
}
wp.ready = ready[:m]
wp.lock.Unlock()
tmp := *scratch
for i := range tmp {
tmp[i].ch <- nil
tmp[i] = nil
}
} - serve 接受HTTP请求的入口
从连接池里获取worker,然后让worker去处理,如果是新建的worker会起一个协程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43func (wp *workerPool) Serve(c net.Conn) bool {
// getCh会获取协程worker,如果是新建的worker会起一个协程。
ch := wp.getCh()
if ch == nil { //说明worker达到最大数目
return false
}
// 这里使用channel,与worker里的协程通信
ch.ch <- c
return true
}
// 获取worker
func (wp *workerPool) getCh() *workerChan {
var ch *workerChan
createWorker := false
wp.lock.Lock()
ready := wp.ready
n := len(ready) - 1
if n < 0 {
if wp.workersCount < wp.MaxWorkersCount {
createWorker = true
wp.workersCount++
}
} else {
ch = ready[n]
ready[n] = nil
wp.ready = ready[:n]
}
wp.lock.Unlock()
if ch == nil { // read取不到,且未达到最大,则新建worker
if !createWorker {
return nil
}
vch := wp.workerChanPool.Get()
ch = vch.(*workerChan)
go func() {
wp.workerFunc(ch) // 在协程里处理链接,通过channel接受HTTP链接
wp.workerChanPool.Put(vch)
}()
}
return ch
} - workerFunc 真正处理链接的地方
主要是一直for循环等channel里出现新的HTTP链接,然后接受HTTP链接去处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39func (wp *workerPool) workerFunc(ch *workerChan) {
var c net.Conn
var err error
for c = range ch.ch {
if c == nil { // 说明,自身长时间未获取到新的HTTP请求导致超时被关闭或者workerpool停止。
break
}
// 使用Server注册的WorkerFunc真正处理HTTP链接
if err = wp.WorkerFunc(c); err != nil && err != errHijacked {
errStr := err.Error()
if wp.LogAllErrors || !(strings.Contains(errStr, "broken pipe") ||
strings.Contains(errStr, "reset by peer") ||
strings.Contains(errStr, "request headers: small read buffer") ||
strings.Contains(errStr, "unexpected EOF") ||
strings.Contains(errStr, "i/o timeout") ||
errors.Is(err, ErrBadTrailer)) {
wp.Logger.Printf("error when serving connection %q<->%q: %v", c.LocalAddr(), c.RemoteAddr(), err)
}
}
if err == errHijacked {
wp.connState(c, StateHijacked)
} else {
_ = c.Close()
wp.connState(c, StateClosed)
}
c = nil
// 处理完一个请求后,把自身归返到read里去
if !wp.release(ch) {
break
}
}
wp.lock.Lock()
wp.workersCount--
wp.lock.Unlock()
}