PHP 数组的底层实现是散列表(也叫 hashTable ),散列表是根据键(Key)直接访问内存存储位置的数据结构,它的 key - value 之间存在一个映射函数,可以根据 key 通过映射函数得到的散列值直接索引到对应的 value 值,无需通过关键字比较,在理想情况下,不考虑散列冲突,散列表的查找效率是非常高的,时间复杂度是 O (1)。
我们先了解几个基础概念.
散列:是一种用常数平均时间执行查找,删除,添加的技术。通常是把输入的字符换算成一个固定数字或是字符串返回。也就是同一个字符串无论输入几次计算散列(hash)值,在条件不变的情况,都是同一个输出值。
一个常见的散列函数
1 | hash(char *str,int tableSize) |
2:虽然散列能实现快速的定位到元素在数组中的位置,但是不同的字符串通过散列计算有可能会得到同一个散列值。这叫做hash冲突,常见的解决hash冲突的是拉链法,或者叫做列表法,也是在同一个数组的位置上存储了一个链表。这也是PHP的解决方法。
3:PHP5的数组实现:
查找关键字时,PHP将计算哈希值,然后遍历“可能”值的链接列表,直到找到匹配的条目。
这是链接冲突解决的说明:
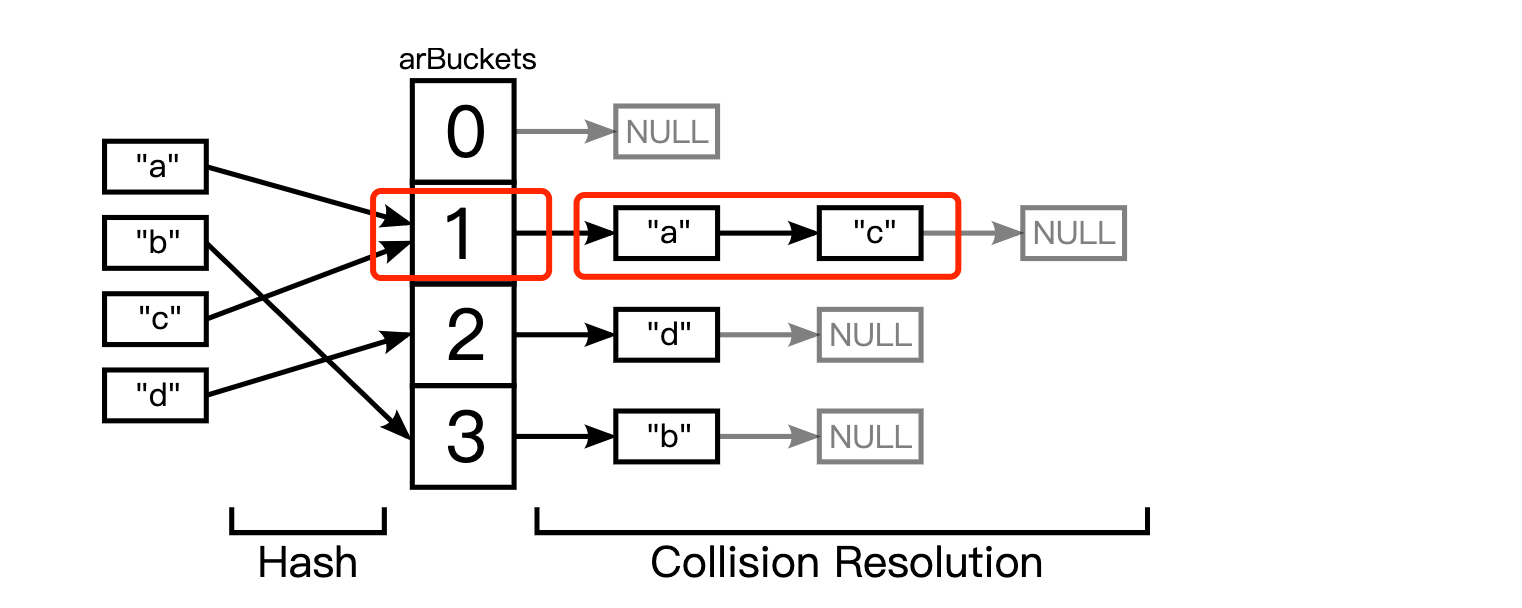
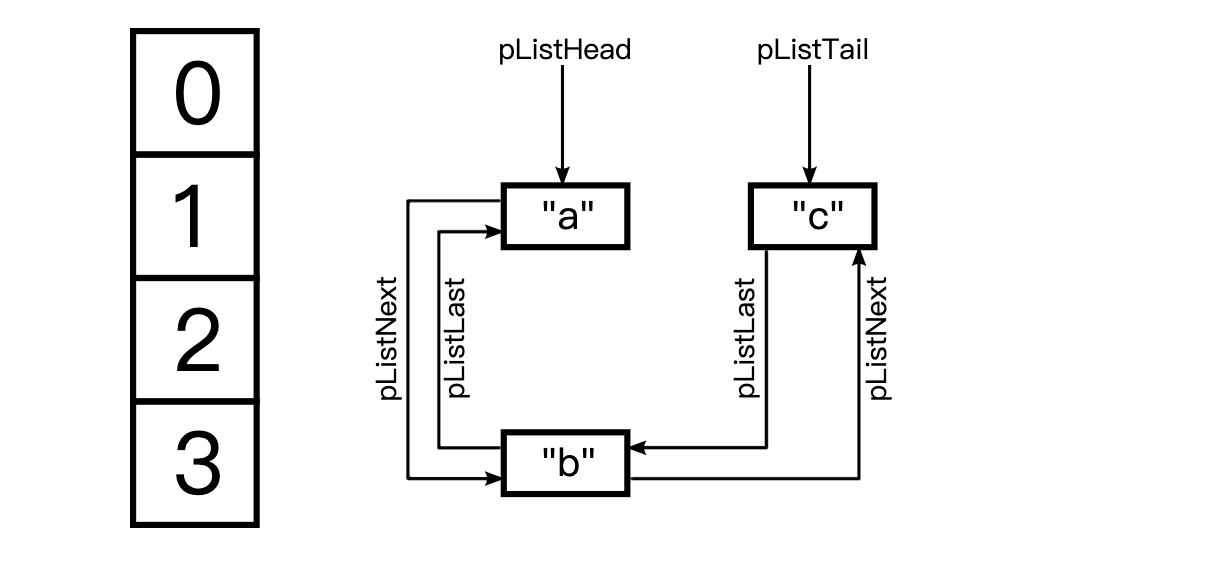
此外,PHP哈希表是有序的:如果遍历数组,您将以插入元素的顺序获得元素。为此,存储桶必须是另一个指定顺序的链表的一部分。由于与上述相同的原因(并且支持反向顺序遍历),这再次是一个双链表。前向指针存储在中pListNext,后向指针存储在中pListLast。另外,哈希表结构具有指向列表开头(pListHead)和列表结尾()的指针pListLast。下面是这个链表可能看起来怎么样的元素的例子”a”,”b”,”c”(按顺序):
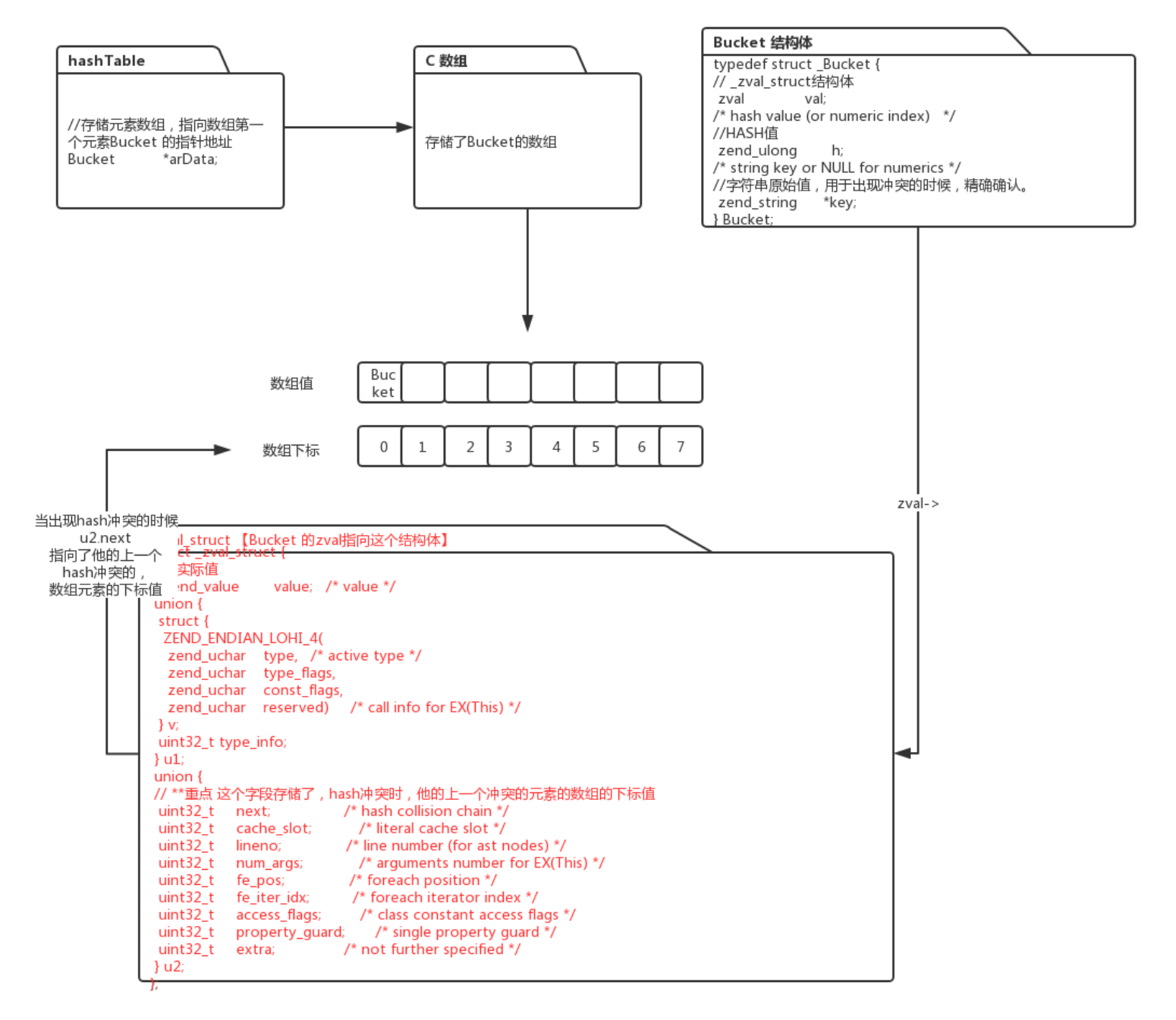
4:php7数组的实现:
PHP7对数组底层实现进行了优化,使得元素的插入顺序和数据的存储顺序保存了一致。
1:下图对PHP数组结构做了接单的梳理
2:PHP有序性的实现方式
为了实现 PHP 数组的有序性,PHP 底层的散列表在散列函数与元素数组之间加了一层映射表,这个映射表也是一个数组,大小和存储元素的数组相同,存储元素的类型为整型,用于保存元素在实际存储的有序数组中的下标 —— 元素按照先后顺序依次插入实际存储数组,然后将其数组下标按照散列函数散列出来的位置存储在新加的映射表中:
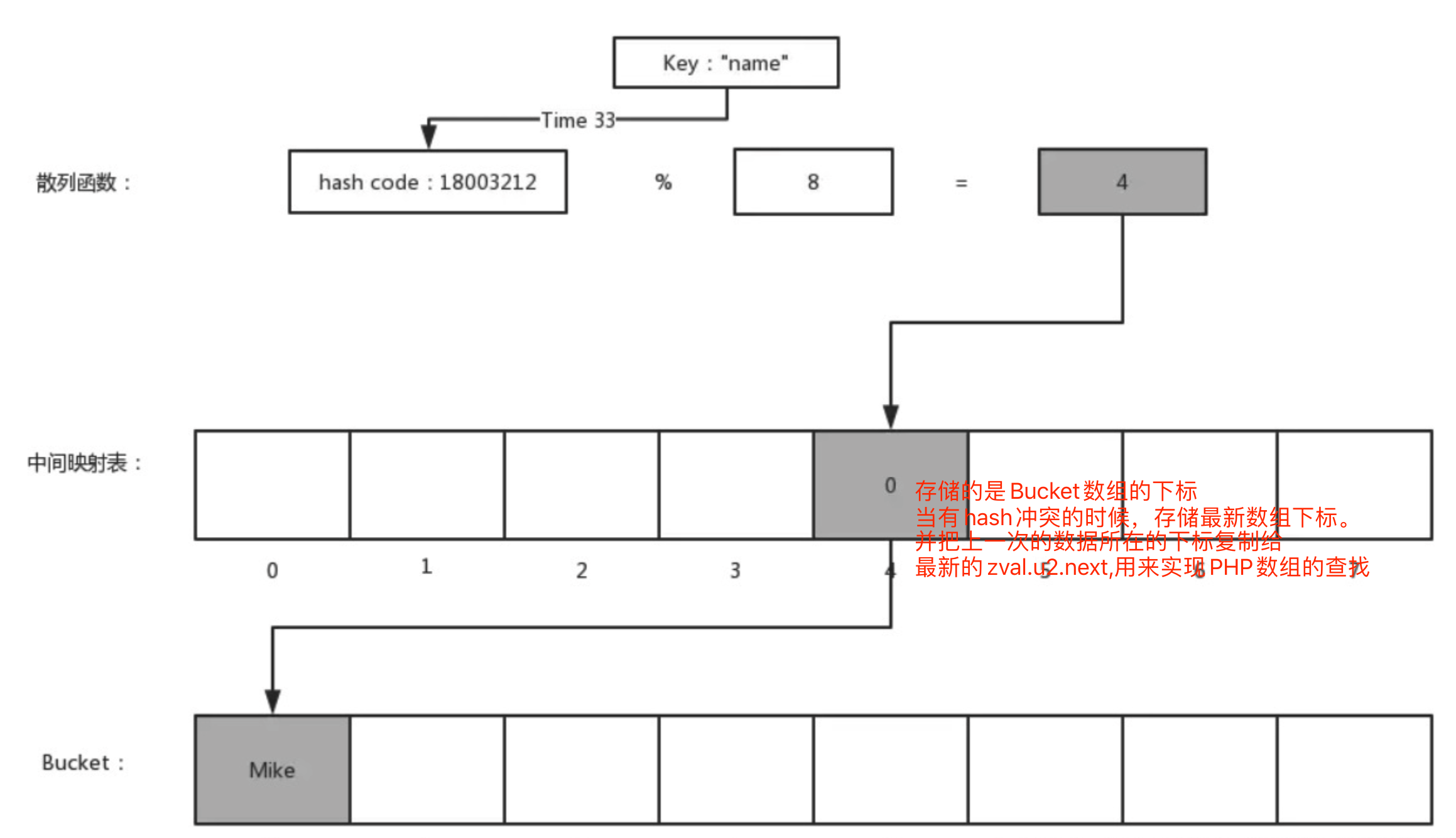
这样,就可以完成最终存储数据的有序性了。
PHP 数组底层结构中并没有显式标识这个中间映射表,而是与 arData 放到了一起,在数组初始化的时候并不仅仅分配用于存储 Bucket 的内存,还会分配相同数量的 uint32_t 大小的空间,这两块空间是一起分配的,然后将 arData 偏移到存储元素数组的位置,而这个中间映射表就可以通过 arData 向前访问到。
3:介绍下各个数据结构
HashTable 位于 Zend/zend_types.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
/* 非常有用 计算出来的hash值与此 进行 | 操作【h | ht->nTableMask】,计算出来存储映射表数组的下标位置。 */
uint32_t nTableMask;
/* 实际存储 数组元素的 指针开始地址*/
Bucket *arData;
/* 已使用数组数量,包括标记删除的,利用这个数字实现数组的有序插入*/
uint32_t nNumUsed;
/* 实际有效元素数量 */
uint32_t nNumOfElements;
/* 已申请的数组的总大小 */
uint32_t nTableSize;
uint32_t nInternalPointer;
zend_long nNextFreeElement;
dtor_func_t pDestructor;
};
/* Bucket:C数组实际存储的值位于 Zend/zend_types.h*/
typedef struct _Bucket {
/* zval_struct 结构体 */
zval val;
/* hash值 */
zend_ulong h; /* hash value (or numeric index) */
/* 字符串元素值,出现hash冲突时候,用来精确确认 是不是所查找的元素*/
zend_string *key; /* string key or NULL for numerics */
} Bucket;
/*
*zval_struct: Bucket的zval所指向的结构体 位于 Zend/zend_types.h
*/
struct _zval_struct {
/* 实际值*/
zend_value value; /* value */
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar type, /* active type */
zend_uchar type_flags,
zend_uchar const_flags,
zend_uchar reserved) /* call info for EX(This) */
} v;
uint32_t type_info;
} u1;
union {
/*重点 这个字段存储了,hash冲突时,他的上一个冲突的元素的数组的下标值*/
uint32_t next; /* hash collision chain */
uint32_t cache_slot; /* literal cache slot */
uint32_t lineno; /* line number (for ast nodes) */
uint32_t num_args; /* arguments number for EX(This) */
uint32_t fe_pos; /* foreach position */
uint32_t fe_iter_idx; /* foreach iterator index */
uint32_t access_flags; /* class constant access flags */
uint32_t property_guard; /* single property guard */
uint32_t extra; /* not further specified */
} u2;
};
4:PHP 数组的操作
添加操作: Zend/zend_hash.c :797行左右
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
add_to_hash:
/* 已使用元素++*/
idx = ht->nNumUsed++;
/* 有效元素++*/
ht->nNumOfElements++;
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
if ((zend_long)h >= (zend_long)ht->nNextFreeElement) {
ht->nNextFreeElement = h < ZEND_LONG_MAX ? h + 1 : ZEND_LONG_MAX;
}
/* 获取存储数组的下标地址,并且赋值*/
p = ht->arData + idx;
p->h = h;
p->key = NULL;
/*计算出 与映射数组的下标值*/
nIndex = h | ht->nTableMask;
ZVAL_COPY_VALUE(&p->val, pData);
/*
*PHP 数组底层的散列表采用链地址法解决哈希冲突,即将冲突的 Bucket 串成链表
*下边的宏函数有四部操作
* Z_NEXT(p->val) 主要是获取 zval.u2.next所指向的地址
* HT_HASH(ht, nIndex) 是获取中间映射表里所存储的值,然后通过赋值语句赋值给zval.u2.next所指向的地址,用于解决hash冲突,串成链表。
*/
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
/**
* 把最新数组下标值,存储于中间映射表中
*/
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
删除数据
关于数组数据删除前面我们在介绍散列表中的 nNumUsed 和 nNumOfElements 字段时已经提及过,从数组中删除元素时,并没有真正移除,并重新 rehash,而是当 arData 满了之后,才会移除无用的数据,从而提高性能。即数组在需要扩容的情况下才会真正删除元素:首先检查数组中已删除元素所占比例,如果比例达到阈值则触发重新构建索引的操作,这个过程会把已删除的 Bucket 移除,然后把后面的 Bucket 往前移动补上空位,如果还没有达到阈值则会分配一个原数组大小 2 倍的新数组,然后把原数组的元素复制到新数组上,最后重建索引,重建索引会将已删除的 Bucket 移除。
数组查找
清楚了 HashTable 的实现和哈希冲突的解决方式之后,查找的过程就比较简单了:首先根据 key 计算出的散列值与 nTableMask 计算得到最终散列值 nIndex,然后根据散列值从中间映射表中得到存储元素在有序存储数组中的位置 idx,接着根据 idx 从有序存储数组(即 arData)中取出 Bucket,遍历该 Bucket,判断 Bucket 的 key 是否是要查找的 key,如果是则终止遍历,否则继续根据 zval.u2.next 遍历比较。