它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (等同于所有节点访问同一份最新的数据副本)
- 可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
- 分区容错性(Partition tolerance)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择[3]。)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项[4]。理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
也就是说,在分布式系统中P一定存在的,因为种种原因,肯定会出现节点之间网络不互通的情况【比如某个分区断网,断电】。所以要在P的情况下载一致性和可用性之间做出选择。
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。
当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。如果要容忍,那么就会出现数据不一致性,因为网络之间不互通无法做到所有节点数据都更新。
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。
然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。这个时候回锁住分区的服务器知道他们都更新成功,才能对外提供服务,所以降低了可用性。
总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
例子:
让我们考虑一个非常简单的分布式系统。我们的系统由两个服务器$ G_1 $和$ G_2 组成。这两个服务器都跟踪相同的变量$ v $,其初始值为$ v_0 。$ G_1 $和$ G_2 $可以彼此通信,也可以与外部客户端通信。这是我们的系统的外观。
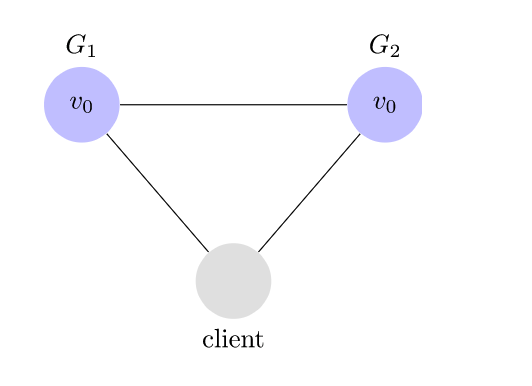
客户端可以请求从任何服务器进行写入和读取。服务器收到请求后,将执行所需的任何计算,然后响应客户端。例如,这是写的样子。
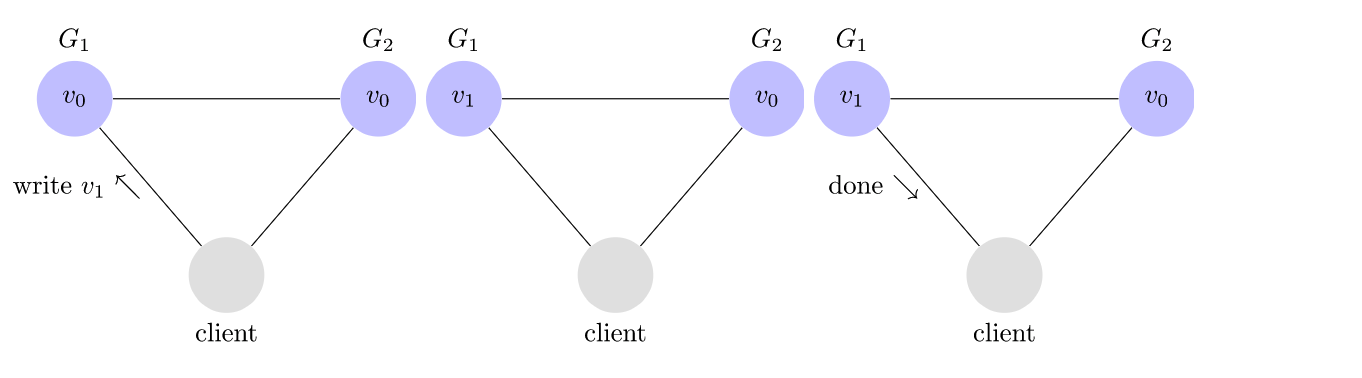
一致性:
在写操作完成之后开始的任何读操作必须返回该值,或者以后的写操作的结果
在一致的系统中,客户端将值写入任何服务器并获得响应后,它期望从其读取的任何服务器取回该值(或更新鲜的值)。
这是一个不一致的系统的示例。【此时G1服务器和G2服务未同步完成数据更新】
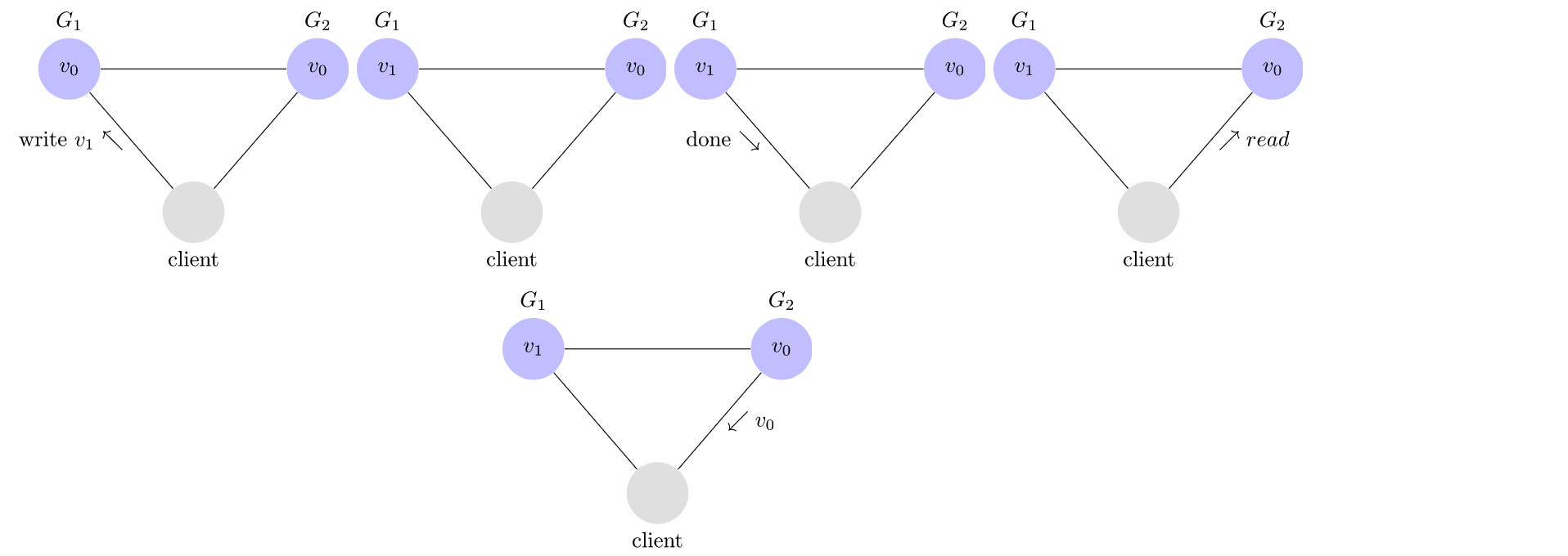
我们的客户将$ v_1 $写入$ G_1 $并且$ G_1 $确认,但是当它从$ G_2 $读取时,它会得到陈旧的数据:$ v_0 $。
另一方面,这是一个一致的 系统的示例。
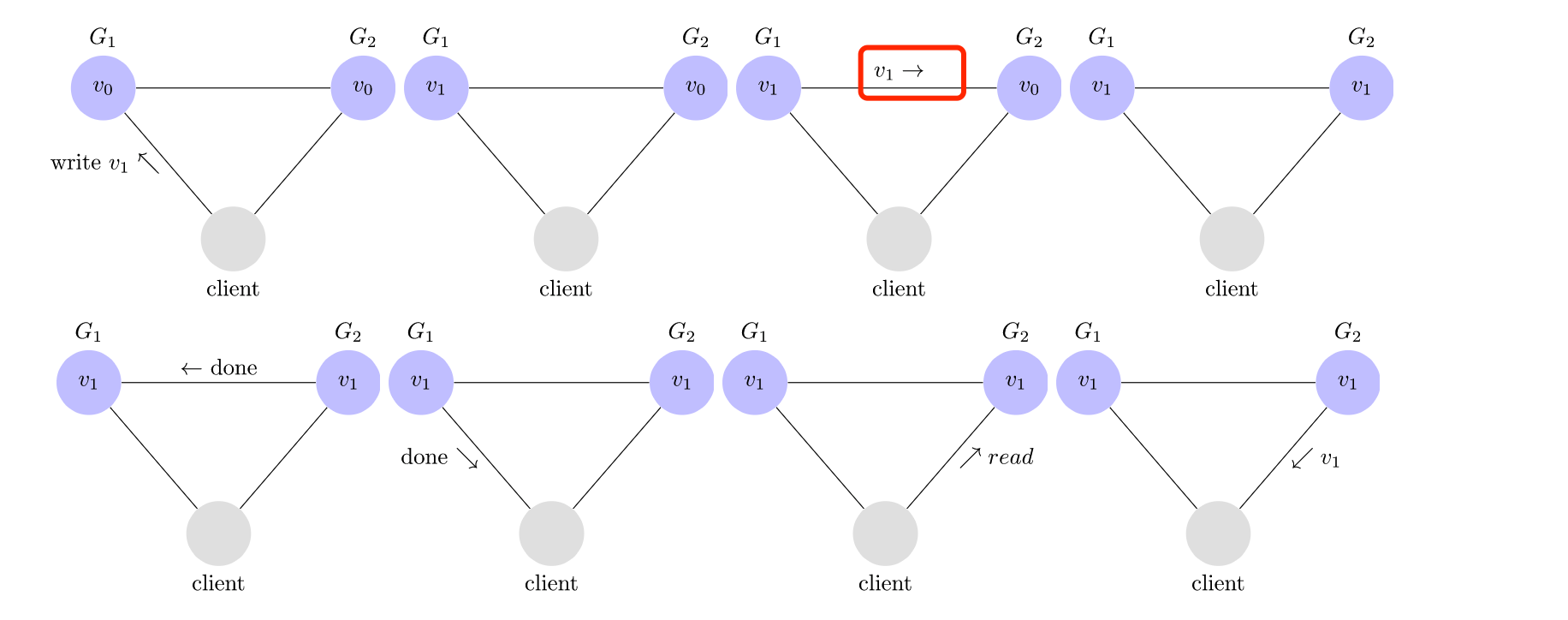
在此系统中,$ G_1 $将其值复制到$ G_2 $,然后再向客户端发送确认。因此,当客户端从$ G_2 $中读取时,它将获得$ v $的最新值:$ v_1 $。
可用性:
系统中非故障节点收到的每个请求都必须导致响应
在可用的系统中,如果我们的客户端向服务器发送请求并且服务器没有崩溃,则服务器最终必须响应客户端。不允许服务器忽略客户端的请求。如上边的不一致性,提高了可用性,但是会造成数据不一致性。
分区容差:
网络将被允许任意丢失从一个节点发送到另一节点的许多消息
这意味着可以丢弃任何彼此发送的消息$ G_1 $和$ G_2 $。如果所有消息都被丢弃,那么我们的系统将如下所示。
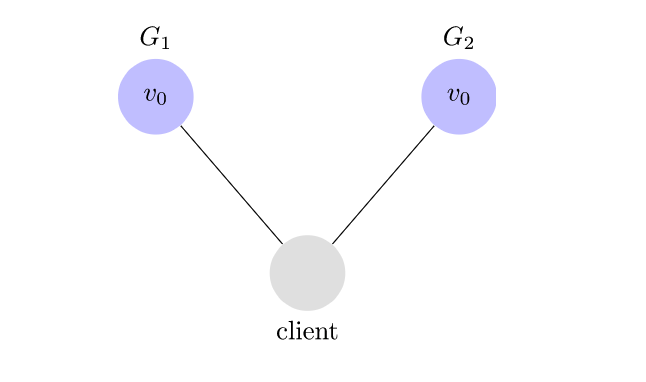
为了容忍分区,我们的系统必须能够在任意网络分区下正常运行。
此时,我们要在C和A之间做一个选择,如果选择C,那么节点之间会一致等待节点之间的互通或数据同步完成,期间会造成服务可用性降低【对客户端请求挂起等等】;如果选择A那么,节点之间会出现数据不一致性。